用户指南 ¶
作者:Robert Andrew Martin
译者:片刻小哥哥
项目地址:https://portfolio.apachecn.org/UserGuide
原始地址:https://pyportfolioopt.readthedocs.io/en/latest/UserGuide.html
这是一本实用指南,主要针对以下内容感兴趣的用户:优化组合某些资产(最有可能是股票)的快速方法。然而,在必要时我会介绍所需的理论,并指出可能适合更先进的优化技术的领域。有关详细信息参数可以在相应的文档页面中找到(请参见侧边栏)。
在本指南中,我们将重点关注均值方差优化 (MVO),这就是大多数人一听到“投资组合优化”就会想到。 MVO 的核心是PyPortfolioOpt 的产品,但值得注意的是,MVO 有多种风格,它们可以具有非常不同的性能特征。请参阅侧边栏,了解各种可能性以及提供的其他优化方法。但目前,我们将继续使用标准的高效前沿。
PyPortfolioOpt 的设计考虑了模块化;下面的流程图总结了PyPortfolioOpt 的当前功能和总体布局。
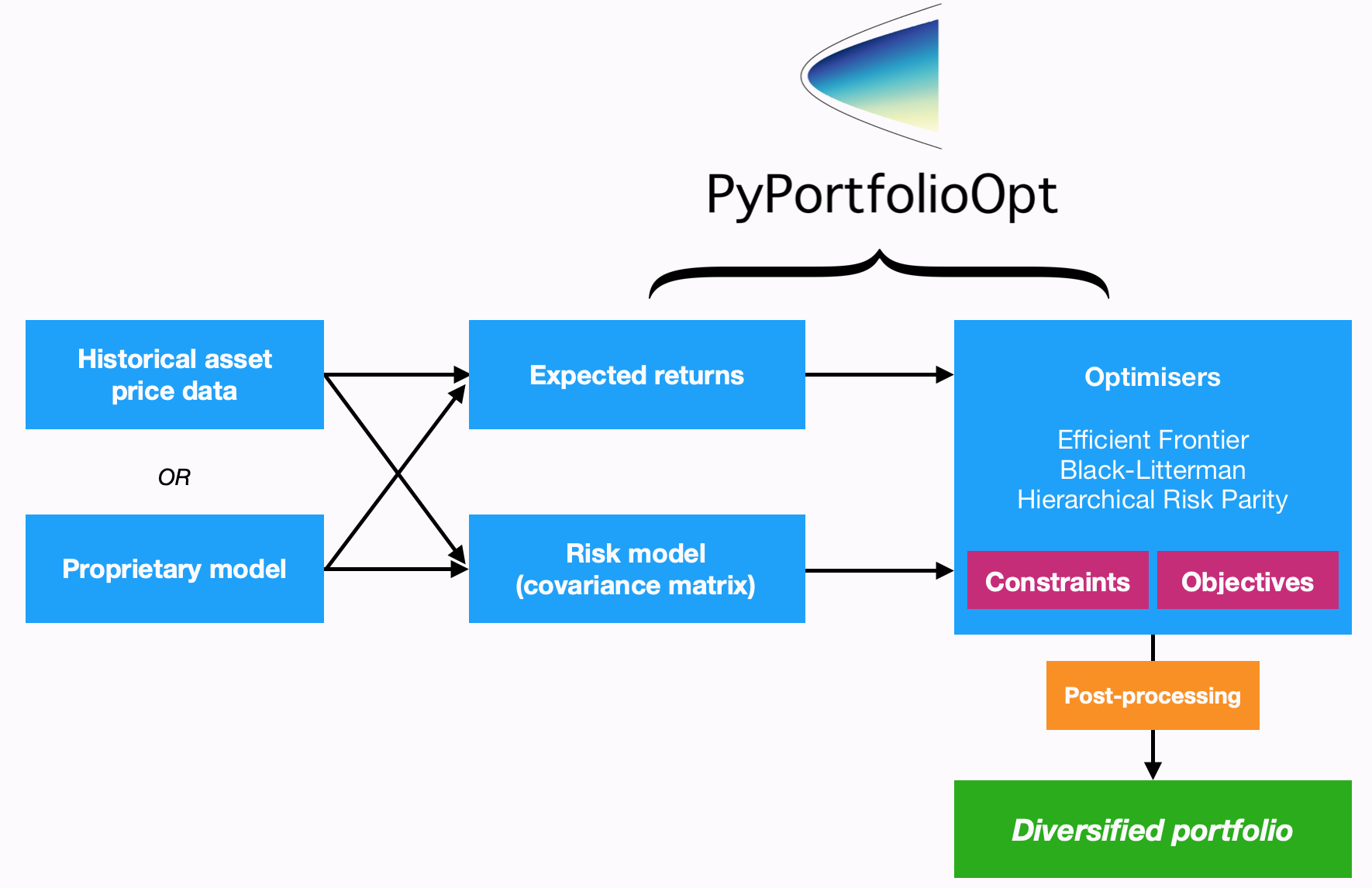
处理历史价格 ¶
均值方差优化需要两件事:资产的预期回报,和协方差矩阵(或者更一般地说, 风险模型 量化资产风险)。
PyPortfolioOpt 提供了估计两者的方法(分别位于 expected_returns 和 risk_models 中),但也支持想要使用自己的模型的用户。
但是,我认为大多数用户(至少在最初)更喜欢使用内置程序。 在这种情况下,您需要提供的只是资产的历史价格数据集。 该数据集应如下所示:
XOM RRC BBY MA PFE JPM
date
2010-01-04 54.068794 51.300568 32.524055 22.062426 13.940202 35.175220
2010-01-05 54.279907 51.993038 33.349487 21.997149 13.741367 35.856571
2010-01-06 54.749043 51.690697 33.090542 22.081820 13.697187 36.053574
2010-01-07 54.577045 51.593170 33.616547 21.937523 13.645634 36.767757
2010-01-08 54.358093 52.597733 32.297466 21.945297 13.756095 36.677460
索引应由日期或时间戳组成,每列应代表 资产价格的时间序列。现实生活中股票价格的数据集 包含在 测试文件夹 GitHub 存储库的。
笔记
定价数据不必是每日的,但频率应该所有资产都相同(存在解决方法,但并不完美)。
将您的历史价格读入 pandas dataframe后 df ,您需要在估计预期收益的可用方法和协方差矩阵之间做出决定。
合理的默认值是 expected_returns.mean_historical_return() 和
协方差矩阵的 Ledoit Wolf 收缩估计 risk_models.CovarianceShrinkage 。只需将相关函数应用于价格数据集即可::
from pypfopt.expected_returns import mean_historical_return
from pypfopt.risk_models import CovarianceShrinkage
mu = mean_historical_return(df)
S = CovarianceShrinkage(df).ledoit_wolf()
mu 将是每个资产的估计预期回报的 pandas series,S 将是估计的协方差矩阵(部分如下所示):
GOOG AAPL FB BABA AMZN GE AMD
GOOG 0.045529 0.022143 0.006389 0.003720 0.026085 0.015815 0.021761
AAPL 0.022143 0.207037 0.004334 0.002954 0.058200 0.038102 0.084053
FB 0.006389 0.004334 0.029233 0.003770 0.007619 0.003008 0.005804
BABA 0.003720 0.002954 0.003770 0.013438 0.004176 0.002011 0.006332
AMZN 0.026085 0.058200 0.007619 0.004176 0.276365 0.038169 0.075657
GE 0.015815 0.038102 0.003008 0.002011 0.038169 0.083405 0.048580
AMD 0.021761 0.084053 0.005804 0.006332 0.075657 0.048580 0.388916
现在我们有了预期回报和风险模型,并准备好继续进行实际的投资组合优化。
均值-方差优化 ¶
均值-方差优化基于 Harry Markowitz 1952 年的经典论文 [1],该论文引领了投资组合管理从艺术转变为科学。 关键的见解是,通过将具有不同预期回报和波动性的资产组合起来,人们可以决定数学上的最佳配置。
如果 \(w\) 是具有预期收益 \(\mu\) 的股票的权重向量,那么投资组合回报等于每只股票的权重乘以其回报,即 \((w^T \mu)\) 。
以协方差矩阵 \(\Sigma\) 表示的投资组合风险由 \(w^T \Sigma w\) 给出。投资组合优化可以被视为凸优化问题,可以使用二次规划找到解决方案。如果我们将目标回报表示为 \((\mu^*)\) ,多头的精确表述投资组合优化问题如下:
如果我们改变目标回报,我们将得到一组不同的权重(即不同权重的投资组合)——所有这些最优投资组合的集合被称为 有效边界 。
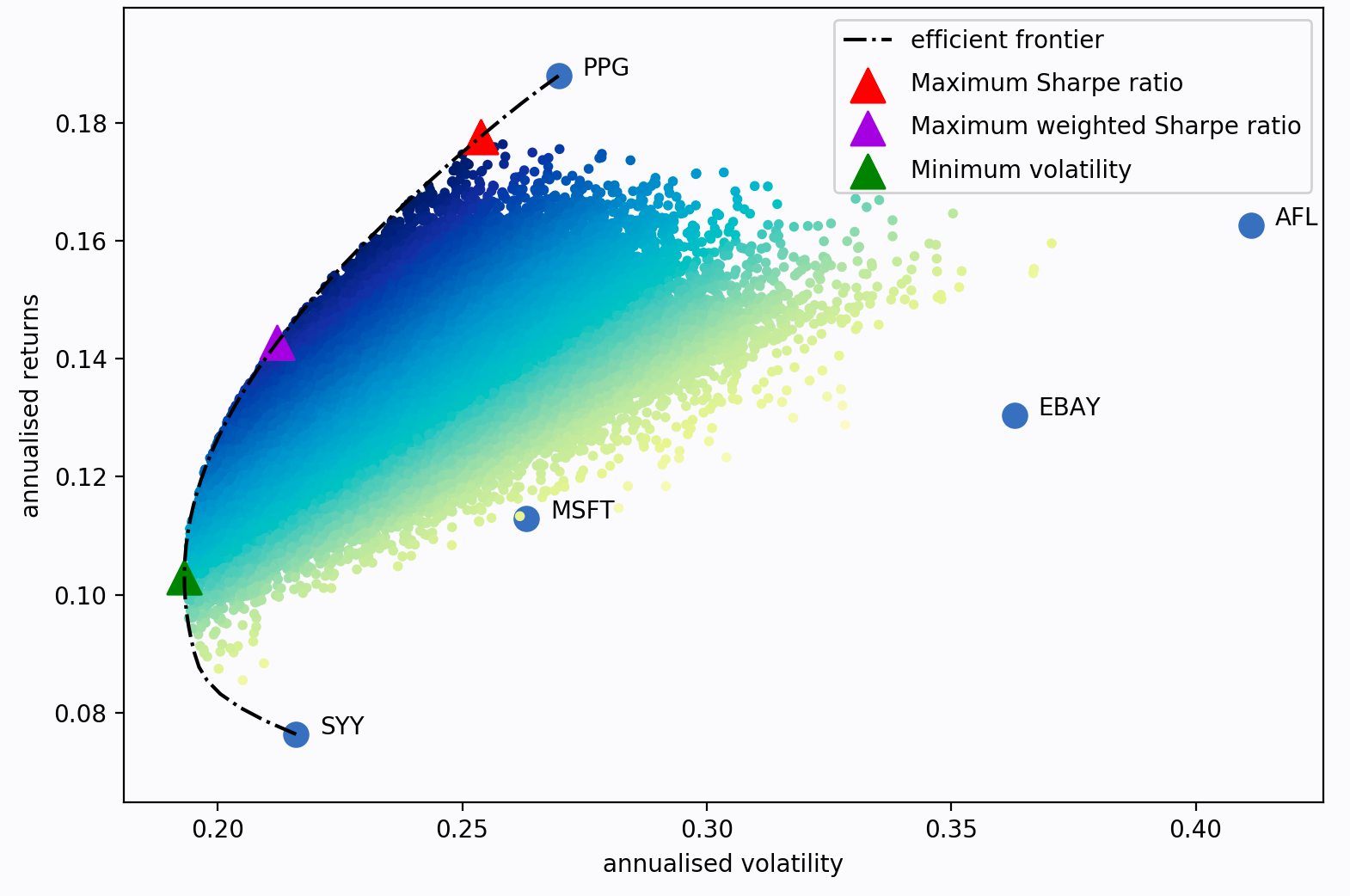
该图上的每个点代表一个不同的可能的投资组合,其中深蓝色 对应于“更好”的投资组合(就夏普比率而言)。虚线的 黑线本身就是有效边界。三角形标记代表 针对不同优化目标的最佳组合。
夏普比率是投资组合超过无风险利率、每单位风险(波动性)的回报。
它特别重要,因为它衡量的是根据风险进行调整的投资组合回报。 因此在实践中,与其试图最小化给定目标回报的波动性(根据 Markowitz 1952),通常更有意义的是找到最大化夏普比率的投资组合。 这是作为 EfficientFrontier 类中的 max_sharp() 方法实现的。 使用之前的series mu 和dataframe S:
from pypfopt.efficient_frontier import EfficientFrontier
ef = EfficientFrontier(mu, S)
weights = ef.max_sharpe()
如果你打印这些权重,你会得到一个相当难看的结果,因为它们会是优化器的原始输出。因此,建议您使用这 clean_weights() 方法,将微小的权重截断为零,并对其余部分进行四舍五入:
cleaned_weights = ef.clean_weights()
ef.save_weights_to_file("weights.txt") # saves to file
print(cleaned_weights)
输出:
{'GOOG': 0.01269,
'AAPL': 0.09202,
'FB': 0.19856,
'BABA': 0.09642,
'AMZN': 0.07158,
'GE': 0.0,
'AMD': 0.0,
'WMT': 0.0,
'BAC': 0.0,
'GM': 0.0,
'T': 0.0,
'UAA': 0.0,
'SHLD': 0.0,
'XOM': 0.0,
'RRC': 0.0,
'BBY': 0.06129,
'MA': 0.24562,
'PFE': 0.18413,
'JPM': 0.0,
'SBUX': 0.03769}
如果我们想知道最优投资组合的预期表现
权重 w ,我们可以使用 portfolio_performance() 方法:
ef.portfolio_performance(verbose=True)
Expected annual return: 33.0%
Annual volatility: 21.7%
Sharpe Ratio: 1.43
优化参数的详细讨论见 通用有效前沿 。然而,有两个主要的变化下面讨论。
空头头寸 ¶
为了允许空头,只需初始化 EfficientFrontier 目的允许负权重的界限,例如:
ef = EfficientFrontier(mu, S, weight_bounds=(-1,1))
这可以扩展到生成 市场中性投资组合(权重总和为零),但出于数学原因,这些仅适用于 effective_risk() 和 effective_return() 优化方法。 如果您想要市场中性的投资组合,请传递 market_neutral=True ,如下所示:
ef.efficient_return(target_return=0.2, market_neutral=True)
处理许多可以忽略不计的权重 ¶
根据经验,我发现均值方差优化通常将许多资产权重设置为零。 如果您出于多元化目的或其他目的需要在投资组合中拥有一定数量的头寸,这可能并不理想。
为了解决这个问题,我引入了一个目标函数,它借用了
机器学习的正则化。本质上,通过增加额外成本
功能达到目标,您可以 encourage 优化器选择不同的
权重(数学细节在 有关 L2 正则化的更多信息 部分)。
要使用此功能,请更改 gamma 范围:
from pypfopt import objective_functions
ef = EfficientFrontier(mu, S)
ef.add_objective(objective_functions.L2_reg, gamma=0.1)
w = ef.max_sharpe()
print(ef.clean_weights())
结果可忽略的权重比以前少得多:
{'GOOG': 0.06366,
'AAPL': 0.09947,
'FB': 0.15742,
'BABA': 0.08701,
'AMZN': 0.09454,
'GE': 0.0,
'AMD': 0.0,
'WMT': 0.01766,
'BAC': 0.0,
'GM': 0.0,
'T': 0.00398,
'UAA': 0.0,
'SHLD': 0.0,
'XOM': 0.03072,
'RRC': 0.00737,
'BBY': 0.07572,
'MA': 0.1769,
'PFE': 0.12346,
'JPM': 0.0,
'SBUX': 0.06209}
后处理权重 ¶
在实践中,我们需要将这些权重转换为实际分配, 告诉您应该购买每种资产的多少份额。这是讨论的 进一步在 后处理权重 ,但我们在下面提供了一个示例:
from pypfopt.discrete_allocation import DiscreteAllocation, get_latest_prices
latest_prices = get_latest_prices(df)
da = DiscreteAllocation(w, latest_prices, total_portfolio_value=20000)
allocation, leftover = da.lp_portfolio()
print(allocation)
以下是拥有 20,000 美元投资组合应购买的股票数量:
{'AAPL': 2.0,
'FB': 12.0,
'BABA': 14.0,
'GE': 18.0,
'WMT': 40.0,
'GM': 58.0,
'T': 97.0,
'SHLD': 1.0,
'XOM': 47.0,
'RRC': 3.0,
'BBY': 1.0,
'PFE': 47.0,
'SBUX': 5.0}
提高绩效 ¶
假设您进行了回测,结果并不理想。 你应该尝试什么?
- 尝试分层风险平价模型(参见 其他优化器 ) – 这看起来稳健地优于样本外均值方差优化。
- 使用 Black-Litterman 模型构建更稳定的预期收益模型。 或者,完全放弃预期回报! 大量研究表明,由于难以预测预期回报,最小方差投资组合 (
ef.min_volatility()) 在样本外始终优于最大夏普比率投资组合(即使按夏普比率衡量)。 - 尝试不同的风险模型:众所周知,与样本协方差矩阵相比,收缩模型具有更好的数值特性。
- 添加一些新的客观条款或约束。调整 L2 正则化参数,看看多样化程度如何影响性能。
导游之旅到此结束。前往相应的部分在侧栏中了解有关参数和理论细节的更多信息 PyPortfolioOpt 提供的不同模型。如果您有任何疑问,请在 GitHub 上提出问题,我会尽力及时回复。
如果您想要更多示例,请查看 cookbook recipe。
参考文献 ¶
- [1] Markowitz, H. (1952). Portfolio Selection. The Journal of Finance, 7(1), 77–91. https://doi.org/10.1111/j.1540-6261.1952.tb01525.x
